
¡Tu carrito está actualmente vacío!
Descifrando la Gramática Oculta de las Proteínas: El Lenguaje que Gobierna la Célula
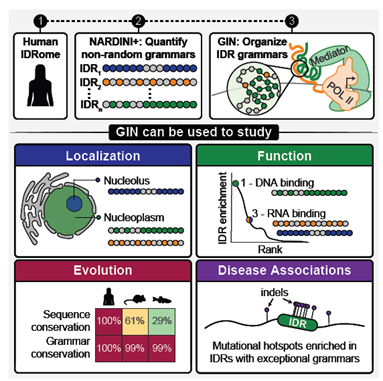
Resumen
Durante décadas, hemos imaginado las proteínas como máquinas rígidas y estructuradas. Sin embargo, una gran porción del proteoma humano está compuesta por regiones “desordenadas” que desafían esta visión. Un innovador estudio publicado en Cell por Kiersten M. Ruff y colaboradores presenta un marco revolucionario para comprenderlas: las “gramáticas moleculares”. A través de herramientas computacionales llamadas NARDINI+ y GIN, los investigadores han creado un diccionario de las reglas sintácticas y semánticas que rigen estas regiones. Han demostrado que estas gramáticas dictan dónde va una proteína en la célula, qué función cumple y cómo sus “errores gramaticales” pueden conducir a enfermedades como el cáncer, lo que abre una nueva era en nuestra capacidad para leer y, eventualmente, escribir el lenguaje de la vida.

Más Allá de la Estructura: El Universo Desordenado de las Proteínas
En el dogma clásico de la biología, la función de una proteína está inseparablemente ligada a su estructura tridimensional. Pensemos en una llave (proteína) que encaja perfectamente en una cerradura (su objetivo molecular). Esta visión ha sido la piedra angular de la biología estructural durante medio siglo. Sin embargo, la realidad es mucho más compleja y fascinante. Una parte significativa de nuestras proteínas, a veces más del 30%, presenta segmentos que carecen de una estructura fija y estable. Son las llamadas Regiones Intrínsecamente Desordenadas (IDRs, por sus siglas en inglés).
Durante mucho tiempo, estas regiones fueron consideradas como el “lado oscuro” del proteoma: difíciles de estudiar, aparentemente caóticas y, para algunos, mero “ruido” evolutivo. Hoy sabemos que son todo lo contrario. Estas regiones flexibles y dinámicas son centros neurálgicos de regulación celular, mediando interacciones cruciales, formando compartimentos celulares sin membranas (condensados) y actuando como interruptores moleculares. La gran pregunta era: si no tienen una estructura fija, ¿qué rige su función? ¿Son simplemente una “sopa” aleatoria de aminoácidos, o existe un código oculto en su secuencia?
NARDINI+ y GIN: Los Lingüistas de la Biología Molecular
El trabajo de Ruff y su equipo nos ofrece la respuesta a través de una poderosa analogía: el lenguaje. Argumentan que las IDRs no son cadenas aleatorias, sino que están escritas siguiendo un conjunto de “gramáticas moleculares”. Al igual que el español tiene reglas sobre el orden de las palabras (sintaxis) y qué palabras usar en un contexto (semántica), las IDRs tienen reglas sobre la composición y el patrón de sus aminoácidos.

Para descifrar este lenguaje, desarrollaron dos herramientas computacionales clave:
- NARDINI+: Actúa como un “revisor gramatical”. Este algoritmo analiza la secuencia de una IDR y cuantifica sus reglas. No solo mide qué aminoácidos son más frecuentes, sino también cómo se distribuyen. Por ejemplo, ¿los aminoácidos con carga positiva están agrupados en bloques o mezclados uniformemente con los de carga negativa? NARDINI+ convierte estas propiedades en una “huella digital” numérica única para cada IDR.
- GIN (Grammars inferred using NARDINI+): Es el “diccionario” o la “biblioteca” de estas gramáticas. Los investigadores aplicaron NARDINI+ a todas las IDRs predichas en el genoma humano (el “IDRome”) y utilizaron algoritmos de aprendizaje automático para agruparlas. El resultado es un recurso monumental: un atlas que organiza los miles de gramáticas de las IDRs humanas en 30 “familias” o clústeres principales, cada uno con un conjunto distintivo de reglas.

El Significado de la Gramática: Localización, Función y Enfermedad
Con este diccionario en mano, los científicos demostraron que esta gramática no es abstracta; tiene consecuencias biológicas profundas.
El Código Postal Celular: Descubrieron que gramáticas específicas actúan como un código postal molecular, dirigiendo a las proteínas a compartimentos específicos dentro de la célula. Por ejemplo, las proteínas con IDRs ricas en bloques del aminoácido lisina (una gramática del “clúster 23”) se dirigen preferentemente al nucléolo. En cambio, aquellas con IDRs ricas en parches de arginina (clúster 26) van a los “cuerpos de Cajal” (nuclear speckles). Esto no es solo una correlación; lo probaron experimentalmente, demostrando que la gramática de la IDR es el factor determinante para su localización.

Una Sintaxis para Cada Tarea: Diferentes gramáticas están asociadas con funciones moleculares distintas. Los clústeres enriquecidos en ciertos patrones de aminoácidos cargados son típicos de proteínas que interactúan con el ARN, mientras que otros patrones son comunes en factores de transcripción que se unen al ADN. La gramática, por tanto, no solo dice “dónde ir”, sino también “qué hacer”.

Cuando la Gramática Falla: Quizás el hallazgo más impactante es la conexión con la enfermedad. Muchas mutaciones asociadas al cáncer no ocurren en las partes estructuradas de las proteínas, sino en estas regiones desordenadas. El estudio revela que estas mutaciones a menudo actúan como “errores gramaticales” que alteran la función de la proteína. Un ejemplo dramático son las “proteínas de fusión” en el cáncer, donde una translocación cromosómica une partes de dos genes diferentes. Frecuentemente, esto resulta en un dominio estructurado de una proteína fusionado a la IDR de otra. En términos de lenguaje, es como tomar el verbo de una oración y pegarle el sujeto de otra completamente distinta. El resultado es una instrucción molecular aberrante que puede secuestrar la maquinaria celular y promover el crecimiento tumoral.

La Importancia y el Futuro
Este trabajo representa un cambio de paradigma. Nos proporciona un marco conceptual y práctico para pasar de ver las IDRs como secuencias enigmáticas a interpretarlas como mensajes funcionales con reglas definidas. La creación de GIN como un recurso de acceso público democratiza esta capacidad, permitiendo a investigadores de todo el mundo analizar sus proteínas de interés a través del lente de la gramática molecular.

Las implicaciones son enormes. Podríamos empezar a predecir la función de proteínas desconocidas simplemente leyendo su gramática. En medicina, podríamos identificar “errores gramaticales” como biomarcadores de enfermedades o, en un futuro más lejano, diseñar fármacos que corrijan estas instrucciones defectuosas. En biotecnología, abre la puerta al diseño de proteínas sintéticas con funciones a la carta, simplemente escribiendo secuencias con la gramática correcta.
En definitiva, Ruff y sus colegas no solo han publicado un estudio; nos han entregado la Piedra de Rosetta para descifrar uno de los lenguajes más fundamentales de la biología.
Referencia:
Ruff, K. M., King, M. R., Ying, A. W., Su, X., Kadoch, C., & Pappu, R. V. (2026). Molecular grammars of predicted intrinsically disordered regions that span the human proteome. Cell, 189, 1–20. https://doi.org/10.1016/j.cell.2025.10.019 (Nota: La fecha de publicación es un marcador de posición del artículo original).
AI bacterias Biología Sintética CRISPR cáncer envejecimiento Escherichia coli evolución Microbioma microbiota regulación resistencia salud VIH virus
Ultimos Productos
-
Curso de Organismos Modelo en Biología Molecular Febrero 2025
El precio original era: $75.00.$57.00El precio actual es: $57.00. -

-

-
Masterclass: Dinámica y Composición de los Condensados Biomoleculares
El precio original era: $80.00.$60.00El precio actual es: $60.00. -

-



Buscar
Últimos Posts

Últimos Comentarios
Categorías
Archivos
- marzo 2026 (5)
- febrero 2026 (15)
- enero 2026 (21)
- diciembre 2025 (20)
- noviembre 2025 (16)
- octubre 2025 (21)
- septiembre 2025 (17)
- agosto 2025 (17)
- julio 2025 (19)
- junio 2025 (24)
- mayo 2025 (26)
- abril 2025 (49)
- marzo 2025 (20)
- febrero 2025 (10)
- enero 2025 (7)
- diciembre 2024 (8)
- noviembre 2024 (23)
- octubre 2024 (7)
Palabras clave
Sígue las noticias
Te invitamos a registrar tus datos como tu correo electrónico para que puedas recibir las últimas noticias y anuncios de Biología Molecular México

By signing up, you agree to the our terms and our Privacy Policy agreement.