
¡Tu carrito está actualmente vacío!
Nace “MetaGraph”: El Buscador a Escala Planetaria que Hará ‘Googleable’ todo el ADN de la Tierra
En pocas palabras
Los repositorios públicos de secuencias de ADN y ARN, como el NCBI Sequence Read Archive (SRA), contienen una cantidad astronómica de información biológica —petabases de datos—, el equivalente a la biblioteca digital de toda la vida en la Tierra. Sin embargo, hasta ahora, esta vasta biblioteca era como un almacén de libros sin índice: para encontrar algo, había que descargar y leer cada libro uno por uno, un proceso prohibitivamente caro y lento.
Un equipo de científicos ha resuelto este monumental desafío con una nueva herramienta llamada MetaGraph. Es un marco computacional que, por primera vez, permite indexar y comprimir todo este universo de datos genómicos en un formato ultracompacto y totalmente ‘buscable’. MetaGraph transforma petabases (miles de billones) de datos brutos en un índice que cabría en unos pocos discos duros de consumo, con un costo de solo unos 2,500 dólares. Lo más increíble es que permite a los científicos realizar búsquedas de secuencias de ADN, ARN o proteínas a través de toda esta información en cuestión de minutos y por un costo de apenas unos cientos de dólares, algo que antes era simplemente impensable. Es, en esencia, la creación de un “Google para el ADN”, una herramienta que promete acelerar el descubrimiento en biomedicina a una escala sin precedentes.
MetaGraph, el buscador de la biblioteca de Alejandría biológica
Imagina que cada ser vivo en la Tierra —cada humano, animal, planta, bacteria y virus— tiene un libro único escrito en el lenguaje del ADN. Ahora imagina que los científicos han pasado las últimas dos décadas digitalizando millones de estos libros y subiéndolos a enormes bibliotecas públicas en la nube. Estas bibliotecas, conocidas como el Sequence Read Archive (SRA) o el European Nucleotide Archive (ENA), contienen hoy una cantidad de información tan vasta que se mide en petabases, el equivalente a miles de billones de páginas. Esta es, sin duda, la base de datos más importante de la historia de la biología.
Pero aquí está la paradoja: a pesar de tener esta biblioteca monumental, no teníamos un catálogo. Encontrar una secuencia específica —por ejemplo, un nuevo gen de resistencia a antibióticos o un ARN viral— era como buscar una frase en millones de libros sin un índice. La única forma era descargar terabytes de datos y analizarlos uno por uno, un proceso tan lento, caro y computacionalmente intensivo que, en la práctica, era imposible. La mayor parte de este conocimiento permanecía en la oscuridad, inaccesible.
Hasta ahora. Un artículo revolucionario publicado en la revista Nature presenta MetaGraph, una proeza computacional que finalmente nos da el índice para esta biblioteca planetaria. Es el nacimiento de un “Google para el ADN”.
El desafío de la escala: domando el diluvio de datos
El problema al que se enfrentaban los científicos era de una escala casi inimaginable. La cantidad de datos genómicos en los archivos públicos se duplica cada pocos años. Construir un índice que permitiera búsquedas rápidas y precisas sobre petabases de datos requería un enfoque completamente nuevo.

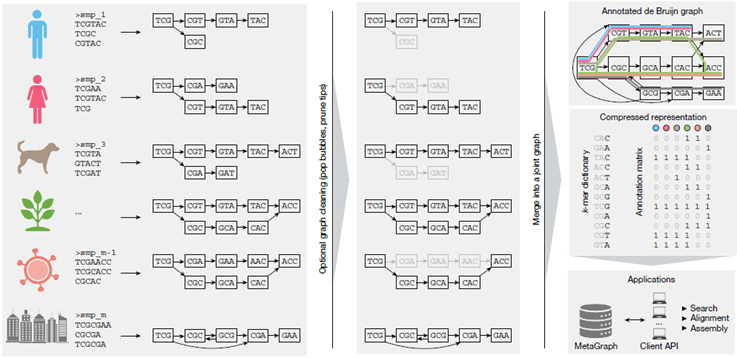
El equipo detrás de MetaGraph, liderado por visionarios en bioinformática, construyó su sistema sobre una estructura de datos elegante y potente: el grafo de De Bruijn anotado. En lugar de almacenar cada secuencia de ADN por separado, MetaGraph la descompone en pequeños fragmentos superpuestos (llamados k-mers) y los organiza en un grafo, una especie de mapa de carreteras donde los fragmentos comunes se fusionan. Esto, combinado con algoritmos de compresión de vanguardia, permite reducir el tamaño de los datos de manera espectacular.
El resultado es asombroso. MetaGraph puede tomar 67 petabases de secuencias de ADN y ARN (el equivalente a todos los datos públicos disponibles en el SRA) y comprimirlos en un índice de aproximadamente 223 terabytes. Esto significa que toda la información genómica pública del mundo podría almacenarse en unos pocos discos duros de alta capacidad que cualquiera puede comprar, por un costo total de unos 2,500 dólares.

Búsquedas que antes eran imposibles, ahora a la orden del día
Pero la compresión de los datos es solo la mitad de la historia. Lo verdaderamente revolucionario es la capacidad de búsqueda. MetaGraph permite a los científicos tomar cualquier secuencia de interés y, en cuestión de minutos u horas, encontrar todas las muestras en la biblioteca global donde aparece esa secuencia. Los costos son igualmente revolucionarios: una búsqueda pequeña puede costar alrededor de 100 dólares, mientras que analizar secuencias más grandes puede costar menos de un dólar por megabase.

Para demostrar su poder, los investigadores realizaron varias búsquedas que antes eran ciencia ficción:
- Vigilancia Global de Resistencia a Antibióticos: Rastrearon la prevalencia de genes de resistencia a antibióticos en miles de muestras de microbiomas intestinales humanos de todo el mundo, identificando tendencias preocupantes, como el aumento de la resistencia a un antibiótico de “último recurso” como la tigeciclina en Sudamérica.
- Descubrimiento de nuevos ARN circulares: Utilizaron MetaGraph para buscar un tipo de molécula de ARN poco estudiada, los ARN circulares, en miles de muestras de tejido humano de los proyectos GTEx y TCGA. Descubrieron miles de nuevos candidatos, algunos de los cuales parecen ser específicos de ciertos tipos de cáncer, abriendo nuevas vías para el diagnóstico.
- Ecología viral: Rastrearon las interacciones entre bacterias y los virus que las infectan (fagos) a escala global, revelando conexiones ecológicas que antes eran invisibles.
Una nueva era para la biomedicina
MetaGraph no es solo una nueva pieza de software; es un cambio de paradigma en cómo interactuamos con la información biológica. Democratiza el acceso a los datos más valiosos de la humanidad, permitiendo que cualquier laboratorio del mundo, no solo aquellos con supercomputadoras, pueda hacer preguntas a escala planetaria.
Abre la puerta a una ciencia más integradora y basada en datos, donde se pueden descubrir nuevas especies, rastrear la evolución de patógenos en tiempo real, identificar biomarcadores para enfermedades y entender la ecología de nuestro planeta a un nivel de detalle sin precedentes. Es el comienzo de una era en la que, finalmente, podemos empezar a leer todos los libros en la biblioteca de la vida.
Referencia del artículo
Karasikov, M., Mustafa, H., Danciu, D., Kulkov, O., Zimmermann, M., Barber, C., … & Kahles, A. (2025). Efficient and accurate search in petabase-scale sequence repositories. Nature. Publicado en línea el 08 de octubre de 2025. https://doi.org/10.1038/s41586-025-09603-w
AI bacterias Biología Sintética CRISPR cáncer envejecimiento Escherichia coli evolución Microbioma microbiota regulación resistencia salud VIH virus
Ultimos Productos
-
Curso de Organismos Modelo en Biología Molecular Febrero 2025
El precio original era: $75.00.$57.00El precio actual es: $57.00. -

-

-
Masterclass: Dinámica y Composición de los Condensados Biomoleculares
El precio original era: $80.00.$60.00El precio actual es: $60.00. -

-



Buscar
Últimos Posts

Últimos Comentarios
Categorías
Archivos
- marzo 2026 (5)
- febrero 2026 (15)
- enero 2026 (21)
- diciembre 2025 (20)
- noviembre 2025 (16)
- octubre 2025 (21)
- septiembre 2025 (17)
- agosto 2025 (17)
- julio 2025 (19)
- junio 2025 (24)
- mayo 2025 (26)
- abril 2025 (49)
- marzo 2025 (20)
- febrero 2025 (10)
- enero 2025 (7)
- diciembre 2024 (8)
- noviembre 2024 (23)
- octubre 2024 (7)
Palabras clave
Sígue las noticias
Te invitamos a registrar tus datos como tu correo electrónico para que puedas recibir las últimas noticias y anuncios de Biología Molecular México

By signing up, you agree to the our terms and our Privacy Policy agreement.